Oct 17, 2023
A deep dive into the world's smartest email AI
Tl;dr - we built an AI assistant for our email app using Retrieval Augmented Generation (RAG). Building and launching a real-world solution that went beyond the basics required a ton of infrastructure work, including AI tech at every level of our stack. Here's what we learned and how our system works at a deep technical level
--
It was late on a Thursday afternoon in November, 2022. Our team was huddled in the basement of a large Victorian house in San Francisco. James Tamplin, our investor and advisor, had called us down here without explaining what he wanted to show us.
"I've been playing with AI", he said, before clicking the "summarize" button in a Chrome extension he'd just built that hooked GPT 3 up to the Shortwave app. I was blown away. While I had been casually following the developments in AI, I was not prepared for the well-written and correct email summary that was produced. Apparently, AI could now do more than just munge text. AI could think.
Our team immediately saw the potential. Each of our users' inboxes contained a vast trove of textual data: human correspondence, calendar invites, receipts, SaaS notifications, newsletters, and so on. We had always wanted Shortwave to help you turn your email history into an actionable knowledge base, but all of our attempts so far using traditional search infrastructure had been underwhelming. LLMs could change that.
Our goal: an executive assistant that lives in your inbox
Summarization was an easy and obvious use case (which we built and launched), but we wanted to aim higher. We believed the reasoning capabilities of LLMs were going to cause a tectonic shift in how users interact with apps, and we wanted to unlock the full potential of this new transformative technology. We wanted to build the next Uber, not the next Hertz mobile app.
After testing many concepts with alpha users, we settled on a simple mental model for our AI that we thought users would intuitively understand: "an AI executive assistant that lives in your inbox". Telling our users to think of our AI like a human sitting next to them, who had perfect knowledge of their email history, helped them reason about what it could do and how best to use it.
The bar had been set – but building it would be no easy task. Human assistants are extremely smart and incredibly versatile. We had our work cut out for us.
How it works – in four steps
We needed an architecture that enabled our AI assistant, over time, to be capable of answering nearly any question. Central to our design, therefore, is the principle that all reasoning about how to answer a question should be handled by the LLM itself. Our job, was to find the right data and stuff it into the prompt.
While we saw other teams building assistants using long chains of LLM calls, with reasoning broken out into stages, we found this approach impractical. In our experience, long LLM call chains introduced data loss and errors at each stage leading to low quality responses. Instead, we settled on a design where the response is generated using a single LLM that includes all context needed to answer the question in one large prompt. This approach relied on an extremely capable large model and a large context window to work. Fortunately, GPT-4 met the mark. We also expected reasoning ability and context windows to improve rapidly over time, so this felt like the right bet to make.
With these principles and the end goal in mind, we worked backwards to figure out what we needed to include in the prompt for the final LLM call to generate a great answer. For example: to answer questions about the user's current email thread or draft, we should include those in the prompt, or to answer questions about a user's schedule we should include data from their calendar. If we had an LLM with an infinite context window and perfect reasoning, and if loading data from our backend was instantaneous, we could just include all info in every LLM call. In a real-world system, however, we have to be very smart about what data we include and what we do not.
To make our system modular and easier to reason about, we introduced an abstraction called a “Tool”. Each type of data (i.e. calendar, email history, draft, etc) would be sourced from a different tool, and the tool would be responsible internally for deciding what specific data to add to the final prompt.
At a high level, our AI Assistant responds to a question in four steps: tool selection, tool data retrieval, question answering, and post processing.
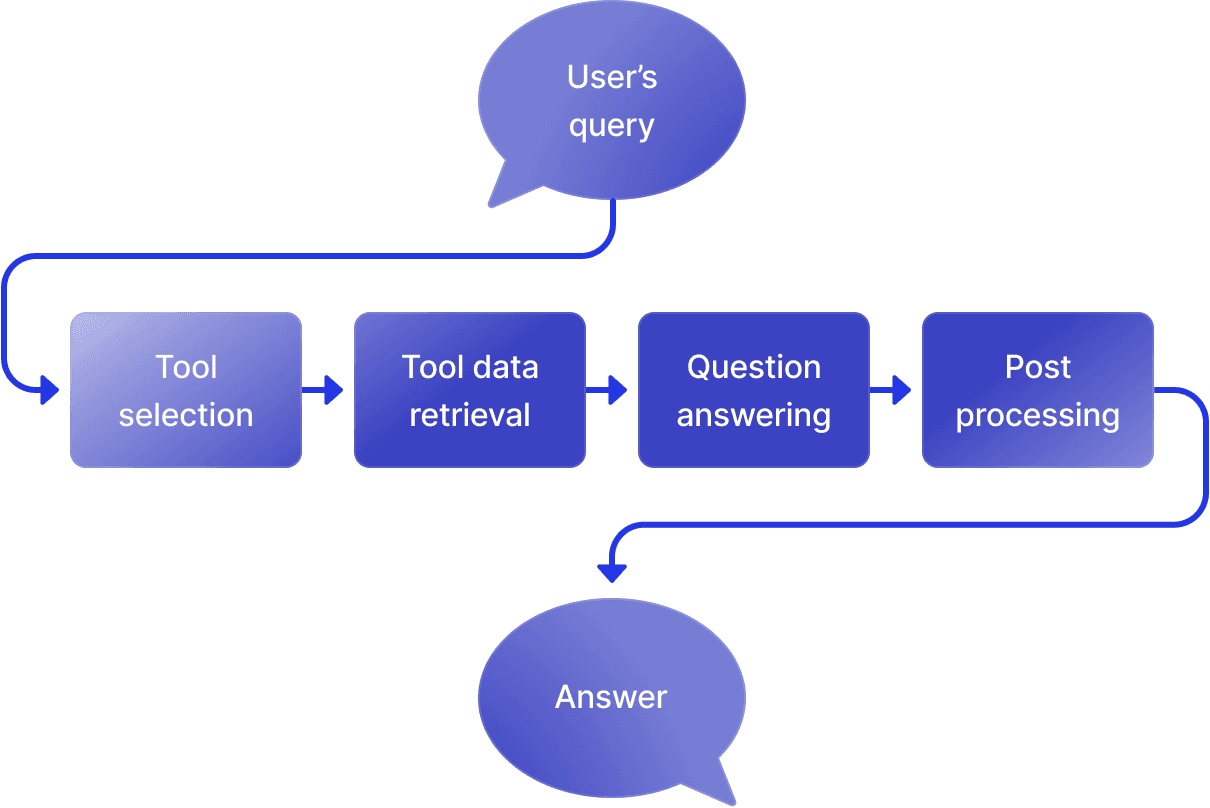
Step 1: Tool selection
When you ask the Shortwave AI a question, it immediately passes that query to an LLM. The purpose of this LLM call, though, is not to answer the question, but to determine the types of data that we need to gather in order to answer the question. We call this step “tool selection”.
Tool selection requires both advanced reasoning capabilities (ie. to differentiate between a general knowledge question and something more personalized that requires email search) and a deep understanding of the context of the question. We use GPT-4 for this step, and we include a lot of detail about the state of the world in our prompt, such as current app state (ie. the current thread the user is viewing), what tools are available, conversation history, and more.
We allow the tool selection to return zero, one or multiple relevant tools. This table illustrates some example user queries, and the tools that the LLM might select for them:
| Query | Tools |
|---|---|
| Summarize this | CurrentThread |
| Reply like I've done in the past | CurrentThread, EmailHistory, Compose |
| What's the longest river in the world? | None |
| Include some free times next week | Calendar, Compose, CurrentDraft |
Tool selection gives us a simple and structured architecture to build and iterate on. Most importantly, it allows us to integrate with multiple, heterogeneous data sources in a modular and scalable way.
Step 2: Tool data retrieval
Once we know what tools we need, we have all of the tools retrieve their data in parallel. Each tool is different. Some are very simple (ie. the “summarize” tool is just custom instructions we include in the prompt) while others are backed by complex distributed systems. Our most powerful and complex tool is EmailHistory (or “AI Search” as we call it in the product). I discuss AI search in detail later in this post.
Most of the heavy lifting in the Shortwave AI Assistant (in fact, most of the AI tech) is actually done inside these modular tools. Tools can make LLM calls of their own, run vector DB queries, run models on our cloud GPU cluster, access our full text search infrastructure, and so on.
Here are some of the tools we provide:
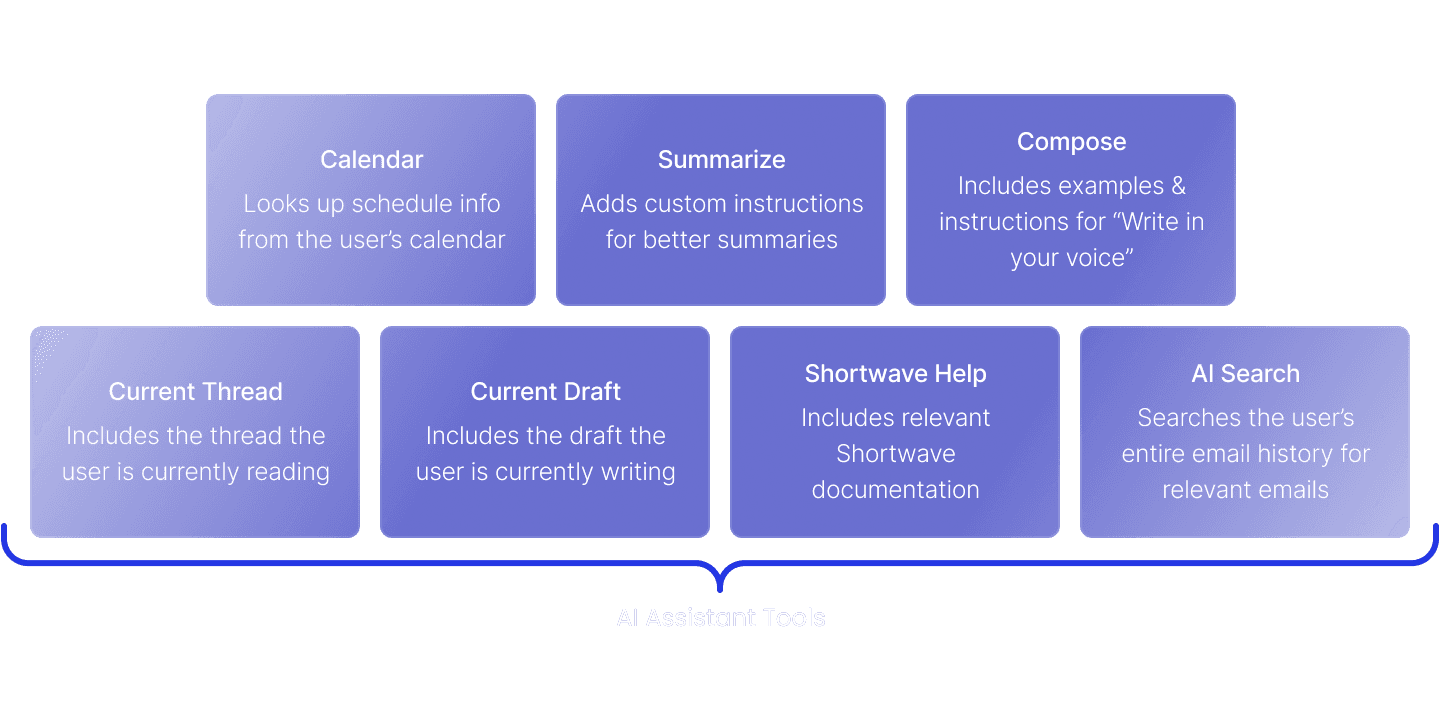
One of our most popular features is our “Write in your voice” capability. This feature is enabled using our Compose tool. When our tool selection step determines that the user is trying to compose an email, we load the info needed to reproduce their voice and tone, including a pre-computed textual description of their style and relevant example emails for few-shot prompting.
Step 3: Question answering
At this stage, we have already collected all the information we need to answer the user's question. All we have to do is create a prompt containing the original user question and all the context information fetched using various tools, and pass it along to an LLM (GPT-4 in our case) to produce an answer. The prompt also contains a lot of specialized instructions, such as how to format the output and cite sources.
This step often requires us to make tradeoffs about how to allocate tokens between different tools. For example, the EmailHistory tool described above usually produces a lot more content than we can fit into a prompt. We use heuristics here to make those tradeoffs when needed.
Step 4: Post-processing
We are almost done! Our post-processing step converts the LLM's output to rich text, adds source citations, and suggests actions to the user (ie. “Insert draft”), so they get a clean and easy-to-use UI to interact with.
Our most important tool: AI Search
Now that you understand our AI Assistant at a high level, let's dive into our most important – and most complex tool. AI search is what enables our assistant to have full knowledge of your email history. It is also what really sets Shortwave's AI Assistant apart from every other email AI assistant product.
The job of AI search is to find emails that are relevant to answering the user's question from across their entire email history, and to rank them by usefulness so that smart tradeoffs can be made during question answering.
AI Search throws a huge amount of CPU and GPU horsepower at every question you ask, and uses a combination of both non-AI and AI infrastructure: LLMs, embeddings, vector DBs, full text search, metadata-based search, cross encoding models, and rule-based heuristics. It is a beast of a system.
Let's break down how this system ticks by following what happens when a query is admitted into the AI search tool.
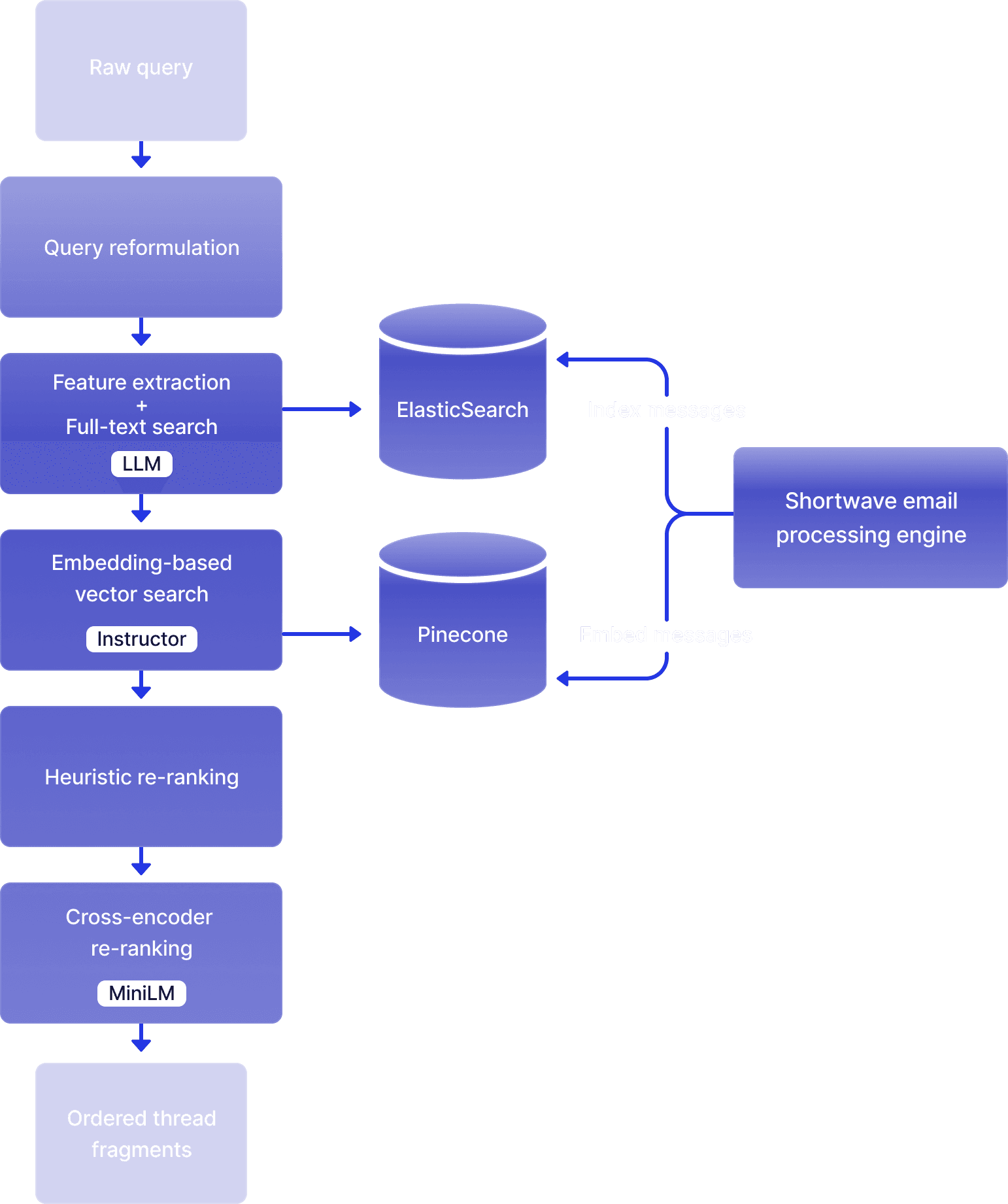
Step 1: Query reformulation
Before we can start looking for relevant emails, first we need to figure out what the user is really asking. For example, consider the following conversation:
User: When do I land in Phoenix?
AI assistant: Your flight to Phoenix on Friday arrives at 6:30 PM.
User: What about Jonny?
The last user question here, “What about Jonny?”, makes no sense as a standalone question. In context though, it is clear that the user is asking “When does Jonny land in Phoenix?”.
Query reformulation solves this problem. It takes a query that lacks needed context, and rewrites it using an LLM so that it makes sense on its own. Query reformulation considers anything that is visible on the screen that the user might be referring to, including the chat history, the currently visible thread, and any current draft. So, for example, you can ask “find similar emails”, and query reformulation would turn that into “Find emails similar to this email about my flight to Phoenix”.
Step 2: Feature extraction and traditional search
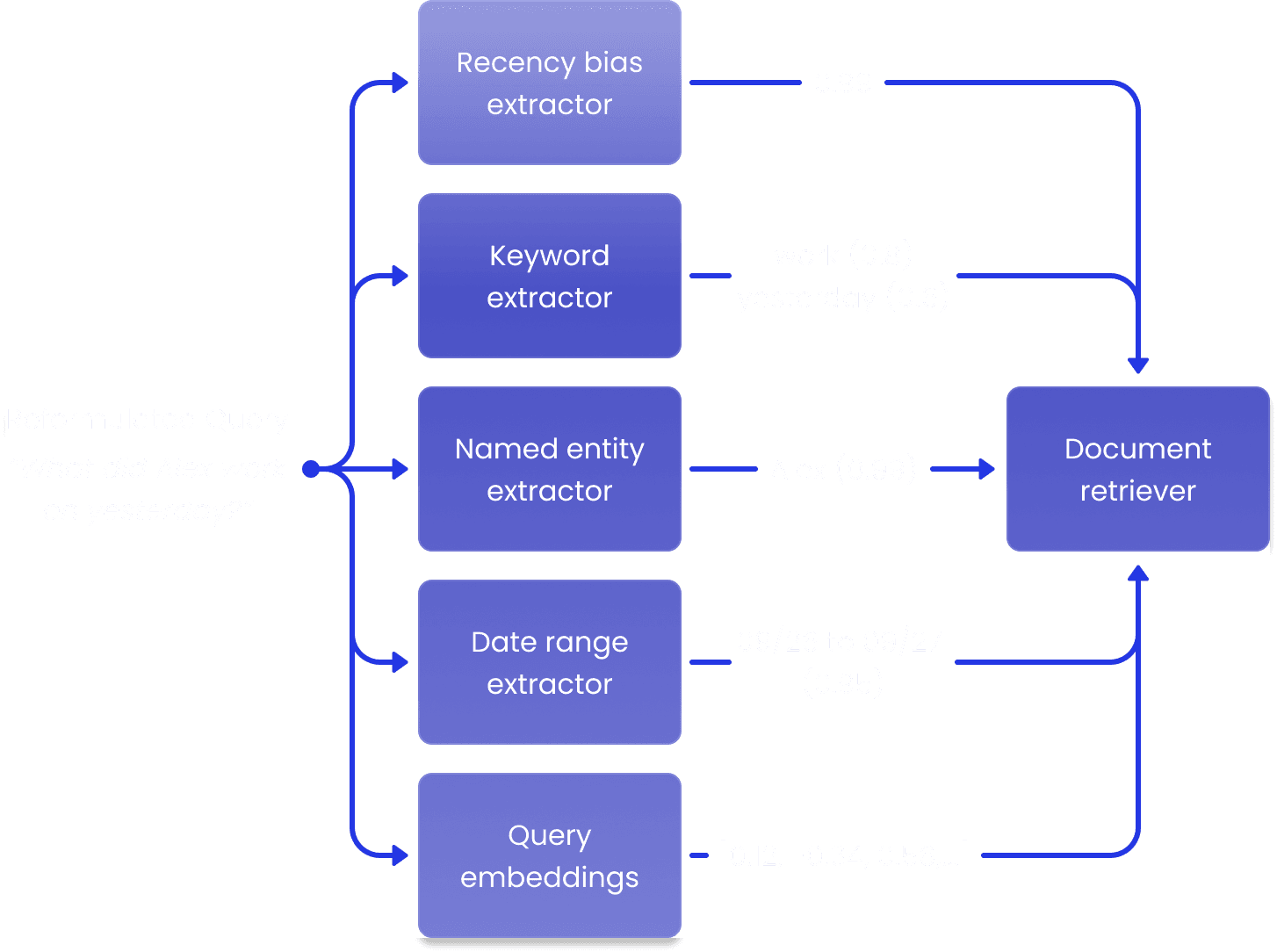
Often, the best way to find relevant emails is to use traditional full-text or metadata-based queries. If we can figure out what queries to run, we can simply use our traditional search infrastructure to find relevant emails.
Fortunately, LLMs can help us out here. We can take our reformulated query and extract a collection of features that describe attributes in the question that might yield useful queries. We look for date ranges, names of people, keywords, email addresses, labels and so on. We do this via a large number of parallel calls to a fast LLM, each optimized to extract a specific feature. Having these LLM calls be independent of each other enables a degree of modularity that makes it easier to test and evolve them. Each extracted feature is also assigned a confidence score, indicating how certain we are about the results.
For example, the query "What did Alex work on yesterday?", may result in a date range feature that covers yesterday, and a name feature that contains “Alex”. The feature extractors have access to relevant context, such as the current system time, so they can resolve ambiguous terms (like "yesterday" and "last week").
Step 3: Embedding-based vector search
In many cases, keyword and metadata-based searches are not enough to find the emails we are looking for. Fortunately, we have a more powerful semantic-aware search technique that can help us in those cases: vector embedding search.
When we ingest an email into Shortwave, we use an open source embedding model (Instructor) to embed the email. We do this on our own servers with GPU acceleration for improved performance, security, and cost. Then, we store that embedding in our Vector database (Pinecone), namespaced per-user (the namespacing is one of the main reasons we chose Pinecone).
When the AI search tool is used, we embed the user's reformulated query and search our vector database for semantically similar emails. This technique can be extremely powerful, because it lets us find emails that are conceptually similar to the question, even if they share no keywords and match none of the features we managed to extract. However, when possible we use some of the features we extracted earlier (e.g. date range) to better scope our semantic search to a smaller subset of the user's email history.
Step 4: Fast heuristic re-ranking
Once we have identified all of the emails from our traditional and embedding search, and we have loaded their metadata, we end up with a big pile of emails to sort through. Often, this results in a thousand or more results – far too many to fit into a prompt. We need to whittle this down to just a few dozen results, and we need to do this fast.
This is where re-ranking comes in. It helps us cut through a lot of low quality potential results to find a handful of really useful emails for answering the user's question. We re-rank emails in two phases: the first phase uses fast heuristics to very quickly cut the list down from a large number to something more manageable for our next machine learning based re-ranking phase.
In the first phase we try to rank the retrieved emails according to their semantic similarity score. This score is readily available for all the emails retrieved from embedding search. For other emails, we directly fetch the relevant embedding vectors from Pinecone, and compute the cosine similarity distance locally.
However, the semantic similarity score is solely a representation of the knowledge contained within the email content. It does not capture other metadata-specific concerns such as labels, dates, and contacts, while the user question may mention some of them. Semantic similarity scores are also sensitive to the various inconsistencies that may be inherent within our embedding model. We overcome these limitations by applying a series of local heuristics based on the features extracted earlier:
- If we previously extracted a date range feature from the query, we apply a Gaussian filter to the similarity scores that boosts the emails that fall within the date range, and penalizes everything else. The exact parameters of the Gaussian filter are tied to the confidence score of the date range feature. This approach enables us to prioritize emails within a specific time period, but continue to consider emails outside that time period with some tolerance.
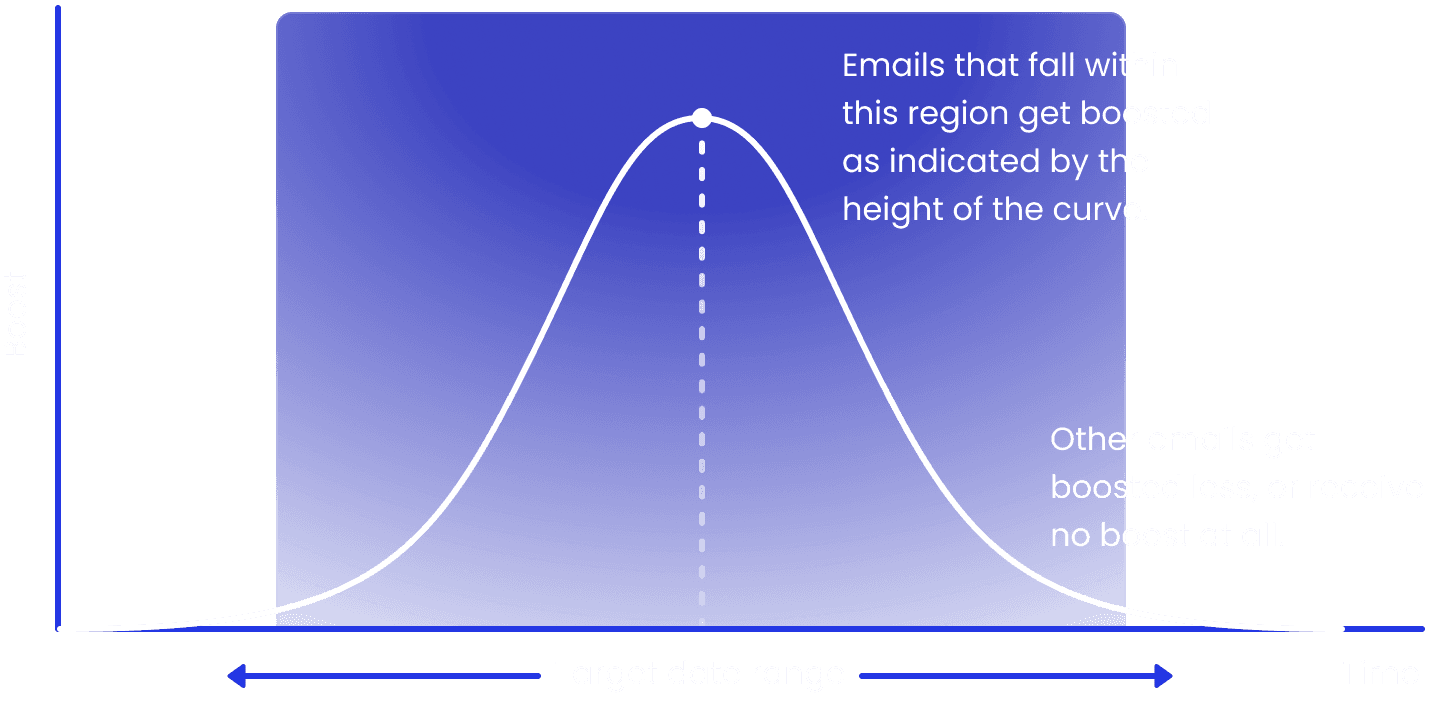
- If we extracted any names or people or email addresses from the query, emails that mention those contacts are given a boost. Again, the magnitude of the boost is determined by the confidence score of the feature.
- If we extracted any label names from the query, emails with those labels get a boost.
- If the query has high recency bias (this is another feature we extract), we boost more recent emails over older emails. This is necessary to correctly handle questions like "Where was our last offsite held?"", that focuses on the most recent offsite over the older ones.
- We de-prioritize Promotions and Updates in favor of other high-value emails.
Once our heuristics have determined the approximate ranking of emails, we start loading their full contents (not just their metadata). For faster performance, we load the emails in small batches, chunking emails into length-capped fragments as we go, and stream them into our second, more expensive re-ranking step.
Step 5: Cross-encoder re-ranking
Our most powerful technique for re-ranking is an open source cross encoding model purpose-built for this task. We use MS Marco MiniLM, running on our own GPUs. The model is smarter than our heuristics, but it is also slow. We therefore take only the top-ranked email thread fragments from the previous step, and process them through a cross-encoder model.
The cross-encoder takes our reformulated query and the pre-selected email fragments as input. It scores each fragment based on its relevance to the question. We then re-apply our local heuristics (the same ones used in the previous phase) to the scores produced by the cross-encoder. This helps boost or penalize fragments based on extracted features and addresses any inconsistencies in the scores. The result is a more robust ordering that considers both semantic relevance and metadata compatibility. We return this final ordered list of fragments to the AI assistant, which uses it to generate an answer to the user's question.
Bringing it all together
Despite the complexity of the system, we have optimized it to be able to answer almost all questions within 3-5 seconds. This end-to-end latency includes multiple LLM calls, vector DB lookups, ElasticSearch queries, calls to open source ML models, and more. The system makes heavy use of concurrency, streaming, and pipelining to pull this off. We also just throw a huge amount of compute at the problem: beefy servers and clusters of high end GPUs.
As you can see, building a real-world, production-ready AI assistant deeply integrated into real application data is a complex task. What you see here is our v1. Our team is continuing to iterate rapidly on our design, so expect our assistant to get smarter, faster, and more capable rapidly over time.
I hope you enjoyed this quick walkthrough of how our assistant works! If you want to see it in action, check out our launch video, or give it a try yourself: Shortwave is free to get started with.
Sign up for monthly updates
Get a roundup of the latest feature launches and exciting opportunities with Shortwave